昨天和大家介紹了Deep&Wide,這2016年於google提出的推薦演算法,最為人稱讚的應是它用2個已知的架構合併,解決廣度與深度問題。
但這個演算法還是有可以改進的地方。例如 wide 的那一半,還需要用到LR的演算法,這樣LR的部份需要預訓練後再放進架構裡
有沒有辦法可以讓整個架構是統一是深度學習框架?不需要做預訓練?
今天要和大家介紹的是2017年華為DeepFM,就可以解決這個問題。
DeepFM 仍然採用 Deep&Wide 架構,就是把負責深度和廣度的兩個模型連接起來,成為一個大的模型來做預測。
但是,DeepFM 做了 2 個部份的改動:
以下是DeepFM架構圖,今天都會圍繞在這張圖來說明:
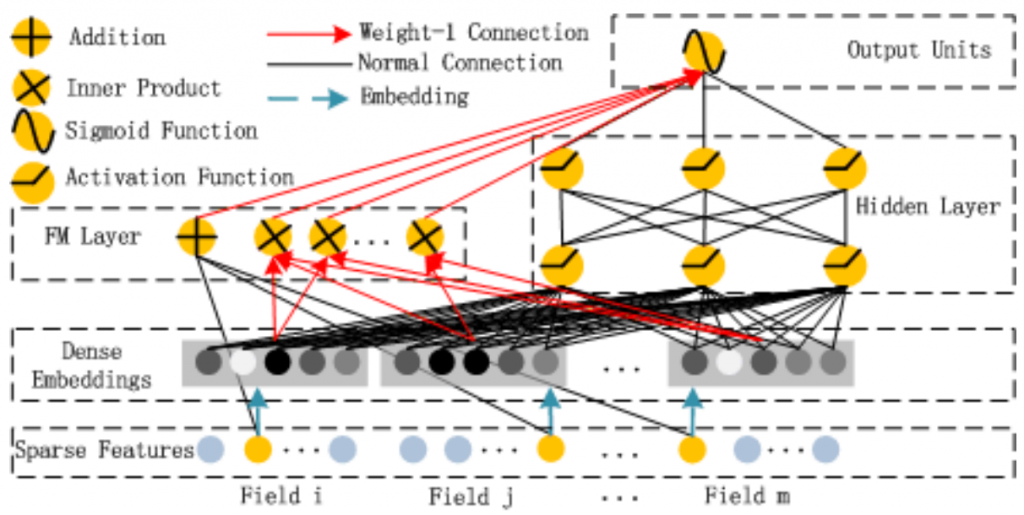
DeepFM 有把FFM裡域的概念帶進來,並讓每個域在 embedding 後都調整成相同維度的向量。
例如:如果我們打算每個域裡的資料,經過embedding後,都調成維度是5的向量。若某個域是連續性的資料(如年齡),最後也會調整維度是5的向量,若某個域是類別型的資料(如:城市),經過 one-hot 編碼後也許維度是上千維,但訓練後,也會得到維度是5的向量。
為什麼要特別提這個變動呢?
這個變動在處理Deep的DNN那邊並沒有什麼影響,反正就是embedding後的每一個域的向量全部連起來成一個大的向量,往DNN輸入。
但在另一邊 Wide 部份,就不一樣了。
剛提到 Wide 部份可以視為是一種有 FM 精神的神經網路架構。
怎麼說呢?我們回想一下FM或FFM有什麼特色:
在 DeepFM 上,他是怎麼實現這些想法的呢?
一階特徴的部份,就是拿sparse Feature 層裡,有非0的部份乘上權重相加於 FM Layer 層,這就是FM公式裡的一階特徵的部份
二階特徵的部份,它是拿任兩個域 embedding 後的向量,做內積於FM Layer 層,這就是公式裡的二階特徵的部份。
有了以上的兩個變動,DeepFM就從需要預訓練及LR,變成完全神經網路的架構。由於它的 Wide 部份有FM 的精神在,所以在處理低階特徵(就是要因果關係很明顯,可以硬背的部份)非常快速有效。

